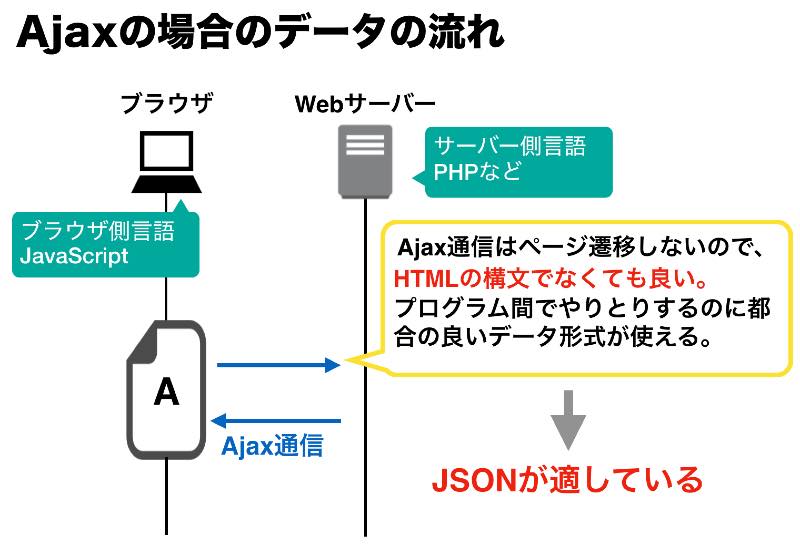
MariaDBの SELECT(参照系)高速化のために試したことを記録しておきます。
2700万件対象のサブクエリ含むSQLに100秒近くかかっていたのが、10秒を切るところまで高速化できました。
環境: さくらのVPS(SSD200GB、メモリ8GB)、CentOS7、MariaDB 10.3.15
主ににやったこと。
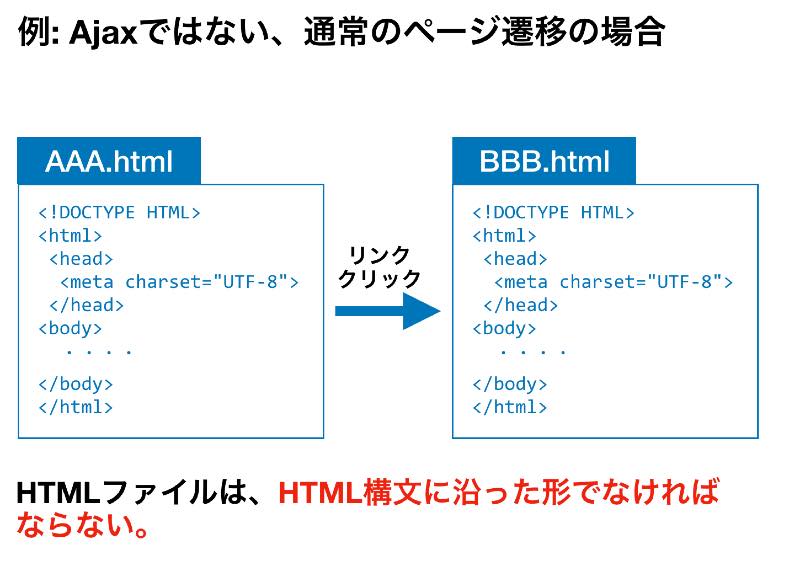
1. index対象のカラムのバイト数削減、EncodingをUS ASCIIに。
2. my.cnfにてグローバル環境設定を行う
3. InnoDBからMyISAMに変更
1. index対象のカラムのバイト数削減、EncodingをUS ASCIIに。
SELECTを高速化するためにindexを定義することは有効ですが、index対象のカラムサイズを節約するとさらに高速化できます。
5倍くらい速くなりました。めちゃ効果あります。
変更前:indexは以下のカラムに対して定義していました。指定するカラムが複数ある複合indexです。
| COL名 | Type | Encoding |
|---|---|---|
| colA | VARCHAR(2) | UTF-8 |
| colB | INT | |
| colC | VARCHAR(4) | UTF-8 |
| colD | INT | |
| colE | VARCHAR(2) | UTF-8 |
explainでクエリ解析した結果は以下。
key_lenが38になってます。
indexを構成するのに1行あたり38バイト必要になっていることを意味します。
| id | select_type | table | type | key | key_len | ref | rows | Extra |
|---|---|---|---|---|---|---|---|---|
| 1 | PRIMARY | <derived2> | ALL | NULL | NULL | NULL | 2000000 | Using temporary; Using filesort |
| 2 | DERIVED | t2 | range | idx_abcde | 38 | NULL | 2000000 | Using index for group-by |
VARCHAR(2)で8バイト使うみたいです。INT型は4バイト消費します。
変更後:これを以下のようにしました。
| COL名 | Type | Encoding |
|---|---|---|
| colA | CHAR(1) | US ASCII |
| colB | TINYINT | |
| colC | CHAR(4) | US ASCII |
| colD | TINYINT | |
| colE | CHAR(2) | US ASCII |
explainは以下です。key_lenが9になりました。
| id | select_type | table | type | key | key_len | ref | rows | Extra |
|---|---|---|---|---|---|---|---|---|
| 1 | PRIMARY | <derived2> | ALL | NULL | NULL | NULL | 2000000 | Using temporary; Using filesort |
| 2 | DERIVED | t2 | range | idx_abcde | 9 | NULL | 2000000 | Using index for group-by |
key_lenを小さくすると、indexで使用する必要バイト数が削減できます。
indexを定義すると、MariaDBはテーブルの領域とは別にindex領域を確保します。これは、紙の本における目次ページのようなものです。目次を載せるには本文とは別に目次用のページが必要ということです。
key_lenが小さいと目次ページが少なくて済みますし、目次を読み込む時間も短くなります。
key_len削減のために以下の変更をしました。
●INTは4バイト領域(最大値2147483647)ですが、ここまで大きな数値が必要ではないカラムはTINYINT(1バイト、最大値127)で置き換えました。
●VARCHARは定義した文字数プラス終端用の領域(2バイト)が必要ぽいのでCHAR型にして必要領域を削減しました。CHAR型は終端バイトが付きません。
●文字型(Encoding)について、UTF-8は1文字につき3バイトほど使います。これを1バイトしか消費しないUS ASCIIに変更しました。
ただし、日本語などマルチバイト文字が入る場合はASCIIは使えません。
このような対応はindexを使用する際に有利というだけでなく、indexを使わないフルスキャンにも有効です。
なぜならば、カラムサイズを節約することでテーブルの全体サイズが小さくなり、フルスキャンする対象も小さくなるからです。
使用したのはこのようなSQL文です。テーブルを5つのカラムでDISTINCTして、さらに特定のカラムでGROUP BYするものです。
サブクエリ外側のSQL文は、一時テーブルに対するクエリになるのでindexが使えず遅くなります。DekaiTableは2700万件、それをDISTINCTしたt1テーブルは200万件あります。

2. my.cnfにてグローバル環境設定を行う
/etc/my.cnf.d/server.cnfの[mysqld]セクションを以下のようにしました。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
# 1. 2回目以降のクエリが高速化する。default:32M <b>query_cache_size = 320M</b> # 2. コネクションのたびに毎回スレッドを作るオーバーヘッドを減らす。default:8 <b>thread_cache_size = 100</b> # 3. MyISAMでソート時に使うバッファサイズ。default:64M <b>myisam_sort_buffer_size = 512M</b> # 4. インデックスを使わないフルスキャン時に利用。default:2M <b>read_buffer_size = 1000M</b> # 5. インデックスブロック用に使用されるバッファメモリ default:402M <b>key_buffer_size = 2000M</b> # 6. クエリキャッシュ最大サイズ default:1M <b>query_cache_limit = 32M</b> # 7. tmp_table_sizeのaliasらしい。MariaDB固有の値。default:16M <b>tmp_memory_table_size = 1000M</b> # 8. 実行時に確保可能な一時テーブル用のメモリサイズ。default:16M <b>tmp_table_size = 1000M</b> # 9. MEMORYテーブルを使う場合の最大サイズを指定。default:16M <b>max_heap_table_size = 2000M</b> # 10. インデックスを使わない結合に利用される。default:262K <b>join_buffer_size = 512M</b> |
グローバル設定はあんまり良くわかってないまま変更したので、改善の余地はまだあると思います。
今回効いてそうなのはtmp_table_sizeです。上記SQLはサブクエリで一時テーブルを作っているはずですので、このバッファを有効に使っていると思われます。
3. InnoDBからMyISAMに変更
MariaDBのデフォルトエンジンはInnoDBですけど、更新が発生しない検索・参照メインのテーブルだとMyISAMの方が高速です。MyISAMに変更して3割くらいSELECTが速くなりました。
ちなみに、MariaDBにはAriaという、MyISAMを洗練させたエンジンがありますが、これはダメでした。index設定しているのに使ってくれない… MyISAMよりも遅くなる結果となりました。
今後に期待したいです。